Ruby on Rail5 速習実践ガイド かんそうぶん
Ruby on Rail5 速習実践ガイド 読みました
というか再読しました。久しぶりの2回目です。
一言で言えば、とてもいい本。教材として選出されるのもよく分かる。
よかったところ
Railsの機能にまんべんなく触れている
標準的なRailsの機能、メジャーなGemにはおおよそ触れているのではないでしょうか。
業務を想定した記述やトピックが充実している
運用を意識したマイグレーションなど、他にも章についても
全編通して、現場で使うのであれば、を意識した文章だったと思います。
定番のカスタマイズやGemの使った実装に触れている
Kaminari、RSpecはもちろんとして、SlimやSidekickなど、
おおよそスタンダードなGemには触れていそうです。
deviseには流石に触れていませんでしたが、入門書ならそれで正解だと思います。
実際の業務でのシステムとの戦い方、改善の仕方に丸一章使っている
業務でチーム開発する際のGitを使ったソースコード管理、コードレビュー、Lint、CI/CD。 さらにRailsにつきまとうバージョンの方法まで紹介しているのは手厚いと思いました。 今でもこれができてない現場はざらにあったりするんじゃないかと思います。
初めて業務につくエンジニアにおすすめしたい本としてみれば
とても参考になると思います。
しかしどうしてもイマイチなところも。
悪かったところ
Rails5 である
ここだけはいかんともしがたいと思います。
2023年現在の実務でRails5を使っているところなんて皆無か、なかなかのレガシー環境だと思います。
フォームdata属性の書き方など、今のRailsとはだいぶ違っているので、
肝心のRailsのトピックを話半分に読み進めなければならないのが、
教材としてはイマイチなポイントでした。
Rails5のキャッチアップをしたいのであれば満点だと思います。
ちょっと時代が古い
バージョンアップのチェックなど、今なら自動テストとdependabotをやRenovateを連携させて、 とかになるんじゃないでしょうか。
学んだこと
いまでも改善の章の記述は参考になると思います。
イケてないプロジェクトの改善運動を推し進めるときに、こういう参考文献があると
自分が実行する上でも周囲を導く上でもやりやすくなるんじゃないでしょうか。
初めて実務につくなら改善より先にコードベースを頑張って理解する方向になるとは
思いますけれど。
難しかったこと
Webpacker は難しいと今でも思います。
初期も初期に手を出して、「これをやるなら一からWebpackを勉強するほうがまだマシだ!」と
裸足で逃げ出した思い出があります。
達人に学ぶDB設計 かんそうぶん
達人に学ぶDB設計を読みました。
ということで以下、感想文。
よかったところ
思っていたよりも易しい本だった
もっと高度で難しくてとっつきにくい本だと思ってました。
その思い込みから、ずっと買ったまま放置していたわけでもあったのですが。
実際にはかなり基礎的なところから説明してくれるので、
DBを専門にしていなくても経験があればスラスラ読めるくらいの難易度でした。
1年か2年くらい実務についたら十分理解できる内容なんじゃなかろうか、
という印象です。
もっと早く読めばよかった・・・!!
「なぜ」を欠かさず説明してくれる
なぜ正規化が良しとされているのか。
なぜ時に正規化が嫌われるのか。
なぜ非正規化が最後の手段なのか。
なぜアンチパターンは生まれるのか。
なぜそれはアンチパターンとされるのか。
そういう部分の説明が必ず入っているので、
通り一遍の形式的な知識にとどまらない教訓を得られる本だったと思います。
「今の業務で使ってるあの構造、アンチパターンなんだ・・・」
なんてところもありました。
悪かったところ
サロゲートキーはアンチパターンなのか?
ここはちょっと首をひねりました。
今日日、主キーをナチュラルキーにしている
データベースには出会ったことがありません。
Railsが複合主キーへ対応し始めたのはつい最近なので、
当たり前といえば当たり前なのかもしれない。
脳死で主キーを振ってモデル分析を怠るんじゃない、と解釈しました。
ボイスコッド正規化の例がよくわからなかった
これはこの本が悪いというより、ボイスコッド正規化が必要な
モデル構造の自体が問題を含んでいるせいかもしれないですが。
こんな不自然なデータモデルある?となってしまいました。
普通は間に関連エンティティが入ったりするから、
なかなか遭遇するものではないのかな、と結論しました。
学んだこと
正規化について正しい理解を得た
今まで経験でマスタ抽出、モデル分割をホイホイとやっていました。
第二とか第三って何?と軽く調べてみたこともあったのですが、
「よくわかんね」であっさりと放置したり。
本書の解説は易しく頭に入りやすいので、すんなり理解できました。
でも自分で設計してたら、あえて第二と第三を区別して正規化なんて
しなさそうですね・・・。感覚で分けちゃいそうです。
それでもERDを眺めて、正規化が甘いところがないかどうか
今までより体系的にチェックできるようになったんじゃないかと思います。
インデックスについて解像度が上がった
チューニングでよく使うよね、くらいの解像度でした。
それでなんとかなってたし、あまり困らなかったのですが。
インデックスの実体や、インデックスがどのようなSQLに効くか、
またトレードオフについても丁寧に解説されていたので、
体系的な知識を得られました。
B-tree以外のインデックスについて軽く調べる機会にもなりました。
しかし、B-treeのBって詳細不明なんですね・・・。
ずっとBinary-treeだと思っていました。
それ二分木や。
難しかったこと
この演習問題は第五正規化しなくていいんですか?
なんとなく関係がありそうなモデルに関連エンティティを繋げた答えを
想定していたのですが、 解答を見たらそんなエンティティは影も形も
ありませんでした。
ここいらないんですね・・・。
シャーディングは難しい
難しいというか、詳しく解説されていないというか。
よくあるベストプラクティス以上を実践するのは、まだ難しそうです。
総括
読んでよかったです。もっと難しい本だと思ってました。さっさと読めばよかった。
新しく得た知識も色々とありますし、曖昧になっていた知識の磨き直しにもなりました。
当分はモデル分析に自信を持って臨めそうです。
OptPerserの使い方
Rubyスクリプトを書いているときに調べたので記事にします。
使い方
基本的にオプションが指定されたかどうかを判定してくれます。 オプションがあればtrueです。
require 'optparse' opt = OptionParser.new container = {} opt.on('-a') {|v| p v } # -a が指定されているかチェック opt.on('-b') {|v| p v } # -b が指定されているかチェック # parse() の場合、ARGVは変更されない。 # オプションを取り除いた結果は argv に設定される。 argv = opt.parse(ARGV, into container) p argv
opt.onでチェックしたいオプションの後ろになにか書くと値付きオプションのチェックになります。引数vはオプションに指定された値になります。
require 'optparse' opt = OptionParser.new container = {} opt.on('-a VAL') {|v| p v } # -a が指定されているかチェック。オプションの値がvに渡ってくる opt.on('-b VAL') {|v| p v } # -b が指定されているかチェック。オプションの値がvに渡ってくる # parse() の場合、ARGVは変更されない。 # オプションを取り除いた結果は argv に設定される。 argv = opt.parse(ARGV, into container) p argv
たとえば、
ruby command.rb -f ~/message.txt
などとすると、opt.on('-f VAL') {|v| p v}の処理で引数vに~/message.txtという文字列が渡ってきます。
DockerでRailsを動かしたときのメモ
Railsの開発環境をDocker化したので、やったことのメモを残します。
基本的には、Dockerfileとdocker-compose.ymlを記述して配置するだけです。
FROM ruby:3.2.2-slim RUN apt-get update -qq && apt-get install -y build-essential libpq-dev nodejs WORKDIR /rails COPY Gemfile Gemfile.lock ./ RUN bundle install
ほとんどDocker公式のままですね。
ADDをCOPYにしたことと、プロジェクトフォルダのコピーをしてないないだけですね。
プロジェクトフォルダは、docker-compose.ymlでマウントするため、コピーしませんでした。
RubyのバージョンはRails側で決まっていたため、3.2.2に指定しています。
services:
web:
build: .
command: bundle exec rails s -p 3000 -b '0.0.0.0'
environment:
- DB_USER=postgres
- DB_PASSWORD=password
volumes:
- .:/rails:cached
ports:
- "3000:3000"
depends_on:
- db
db:
image: postgres:12
environment:
- POSTGRES_PASSWORD=password
volumes:
- pg_datastore:/var/lib/postgresql/data/
volumes:
pg_datastore:
これも定番ですね。
Dockerfileを使ってwebコンテナを作成- DBイメージを使ってdbコンテナを作成
- 永続化のためにDBをボリュームにしてマウント
docker-compose upでサーバーが起動するようにcommandを設定
言及すべき点は、Postgresqlのイメージは起動時に、POSTGRES_PASSWORDの環境変数を必須としていることでしょうか。コンテナ作成時のエラーメッセージにそう書かれていました。
工夫したポイントとしては、webコンテナのDBへの接続情報を環境変数にしたことです。
設定がバラけるのが嫌だったので、composeファイルに集めました。
あとは、ホストのRailsフォルダをcachedでマウントしたことくらいですね。パフォーマンスが良くなるらしいです。
あとはdatabase.ymlに編集を加えて、ユーザーとパスワードを環境変数から読み出すようにするだけです。
そうそう、起動するときは、まず
docker-compose run --rm web bin/rails db:setup でDBを作成した後に
docker-compose upで起動です。
定番ばっかりなので、開発環境だけなら慣れればすぐですね!
何故かGithubの草(コミット履歴)が空白になっていたので雑に直したら悪化した話
ことの経緯から説明します。
長らくWindowsユーザーだったのですが、最近、Macを新調したんです。
技術の勉強用に。
毎日、4時間くらい勉強してはコミットを作って、Githubの履歴に草を生やして楽しんでいたのですが。
そしてある時、気づきました。
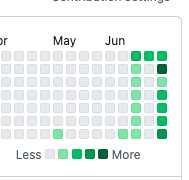
は、禿げてる・・・!
先週のコミットがきれいさっぱり反映されていません。WHY?
調べてみたところ、Macを新調した際にGitのauthorを設定していないためでした。
こちらの記事が参考になりました。
というわけで修正。
メールアドレスを設定して、過去のコミットにメールアドレスを反映します。
$ git config user.email [githubに登録したメールアドレス] $ git rebase -i HEAD~6 $ git commit --amend --reset-author $ git rebase --continue ... $ git push --force
これでよし!Githubを確認すると・・・!
は、禿げてる・・・!
どうやら rebase はコミット日を現在日時で上書きしてしまうそうです。なんてこったい。
と、ここまでが5日くらい前の話。コミット履歴がやたら濃くなってる日ですね。
約一週間分のコミットがこの日に集約されてしまったので、これを修正しようというのが本題です。
ポイントとして、force push をしてしまっても上書きされたコミットが消えてしまったわけではありません。実は、Gitの中にその情報は残っています。
$ git reflog
...
ccfd430 HEAD@{20}: rebase (finish): returning to refs/heads/master
ccfd430 HEAD@{21}: commit (amend): create 03.md
3524422 HEAD@{22}: rebase (edit): create 03.md
1b5a692 HEAD@{23}: commit (amend): create 02.md
7724473 HEAD@{24}: rebase (edit): create 02.md
...
f218827 HEAD@{48}: rebase (edit): create 25.md
441a4ae HEAD@{49}: rebase (start): checkout 441a4ae
f4faf03 HEAD@{52}: commit: create 03.md
...
ありました。
git rebase を start して、edit → amend を繰り返して finish した履歴です。
今回は、この rebase する前の状態をサルベージしたいので、直前の「f4faf03」の履歴を新しいブランチにします。
$ git checkout -b f4faf03 salvage
結果を確認しましょう。
$ git log commit f4faf03235302dcd5134af1c7a73c63314a2fa0b (HEAD -> salvage) Author: user <user@usernoMac-mini.local> Date: Mon Jul 3 23:48:43 2023 +0900 create 03.md commit e1938fdc292cdfe2bf5ff54e5847656f259558ec Author: user <user@usernoMac-mini.local> Date: Sun Jul 2 21:00:09 2023 +0900 create 02.md commit 645bcb9cf4f13b8c7fa410eab0214e12f3f14493 Author: user <user@usernoMac-mini.local> Date: Sat Jul 1 23:24:25 2023 +0900 craete 2023/07/01.md
よしよし、ちゃんとした日時が入っている履歴を掘り起こして、salvage という名前のブランチにすることができました。
では、salvage ブランチのコミットにメールアドレスを設定しましょう。今度は失敗しません。
$ git rebase -i HEAD~20 --committer-date-is-author-date $ git commit --amend --author="ユーザー名 <登録したメールアドレス>" $ git rebase --continue $ git commit --amend --author="ユーザー名 <登録したメールアドレス>" $ git rebase --continue ...
ポイントは2点。
- rebase に --committer-date-is-author-date オプションを付けたこと
- commit 時に --reset-author をつけるのをやめたこと
前者は、rebase の日付更新を防止するため。
後者は --reset-author が日付を上書きしてしまうため。
これでコミットの日付を維持したまま、メールアドレスを設定することができたはずです。
$ git log commit 370fb42cad31c5cd41719cddee82ba1cb8e3104e (HEAD -> salvage) Author: ユーザー名 <登録したメールアドレス> Date: Mon Jul 3 23:48:43 2023 +0900 create 03.md commit 63d1a7395e4caa0d577be0c0f555c60bc7a87951 Author: ユーザー名 <登録したメールアドレス> Date: Sun Jul 2 21:00:09 2023 +0900 create 02.md commit effd8484be3ca554e0b83e93f5bcf61227b5dd33 Author: ユーザー名 <登録したメールアドレス> Date: Sat Jul 1 23:24:25 2023 +0900 craete 2023/07/01.md
完璧ですね!
あとは、このsalvageブランチをプッシュすれば Github に緑が戻ります。
が、せっかくなのでこの salvage ブランチを master ブランチと統合しましょう。
現在の状態を図で表すとこんな感じ。
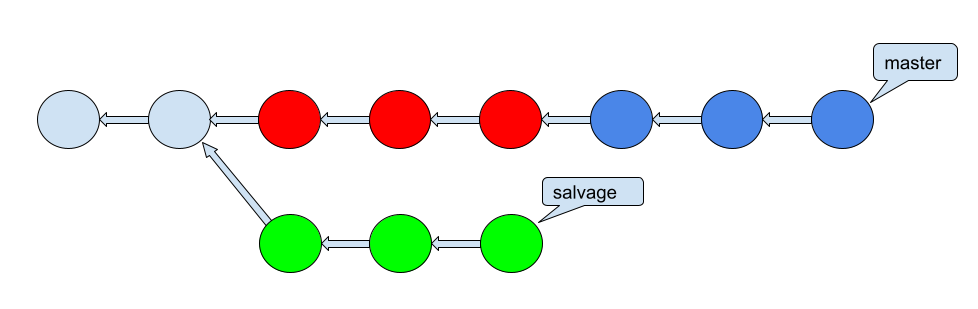
緑のコミットが今回の作業で修正したコミット。
赤いコミットが前回の雑な修正でできてしまった、不要なコミット。
青いコミットが最近作業した新しいコミットです。
これが以下の形になってくれるのが理想です。
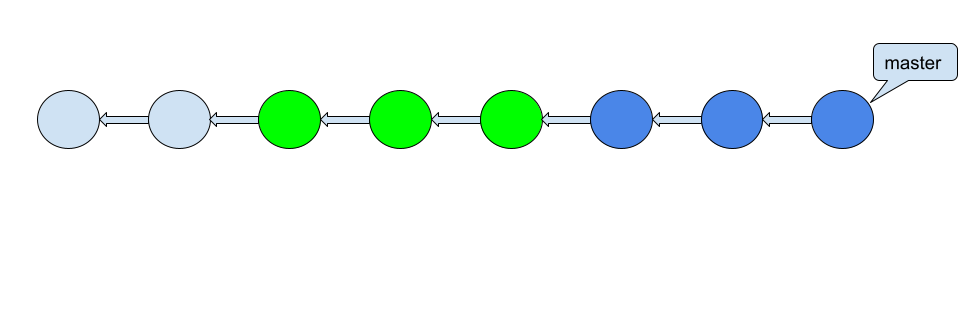
こんなとき、何を使うか。
そうだね、rebaseだね。
赤いコミットと緑のコミットは変更内容が同じなため、rebaseはこのコミットを無視して青いコミットだけ付け替えてくれます。
$ git switch master $ git rebase salvage --committer-date-is-author-date $ git push --force

大勝利!
(一日空いてるのは、この日の勉強が日付をまたいだからですね)
ということで、コミット履歴の修正でした。
コミット履歴の改変は面倒なので、そもそも必要にならないように気をつけるのが一番、というお話でしたとさ。
(他のリポジトリのコミットの修正はどうしましょうか・・・)
Github Pages でWebページを公開する方法
https://chee-se.github.io/resume/
特に難しいことはないのですが、手順を説明していこうと思います。
1. リポジトリを用意する
2. リポジトリを公開する
3. Github Pages を公開する
これだけです。
Github Pages でWebページを公開する方法
1. まずはリポジトリを用意します。
この公開するコンテンツを用意するところが一番大変だと思います。
https://github.com/chee-se/resume
2. リポジトリを公開します。
Github の無料会員は必須です。有料会員は必要ないらしいです。
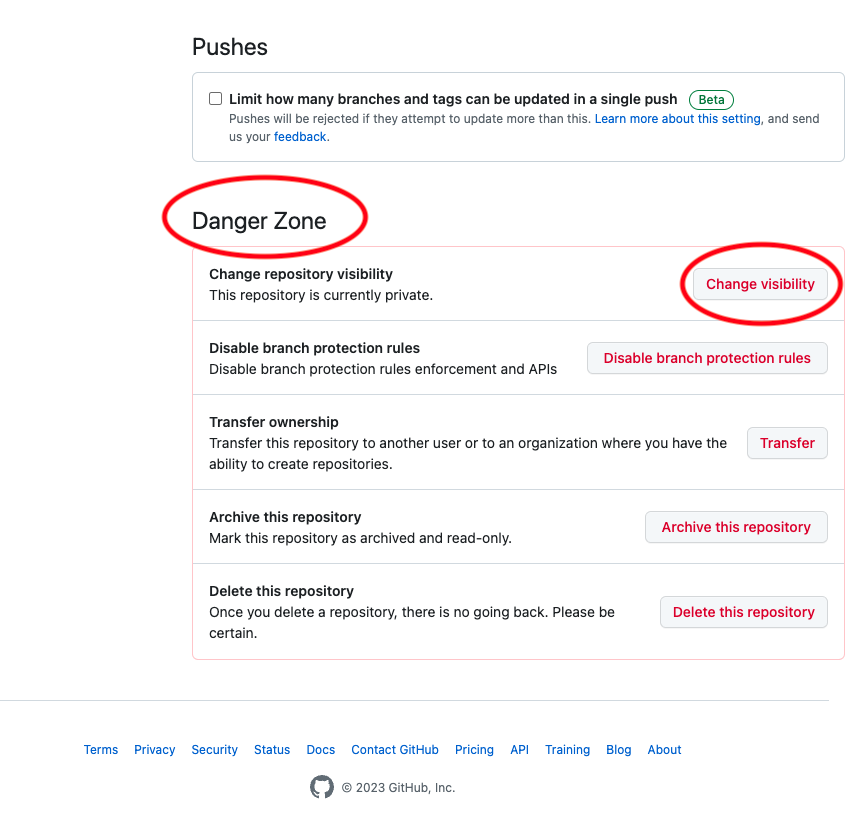
Settings タブをクリック。
一番下までスクロールして、「Danger Zone」の「Change Visibility」をクリック。
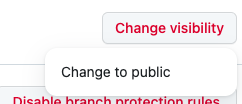
「Change to Public」というツールチップが出てきたらクリック。
※ 「Change to Private」が出てきた場合、すでに公開状態のため押す必要はありません。
諸々の確認ダイアログをクリックして、「Make this repository public」を押したらリポジトリの公開は完了です。
3. GIthub Pages を公開します
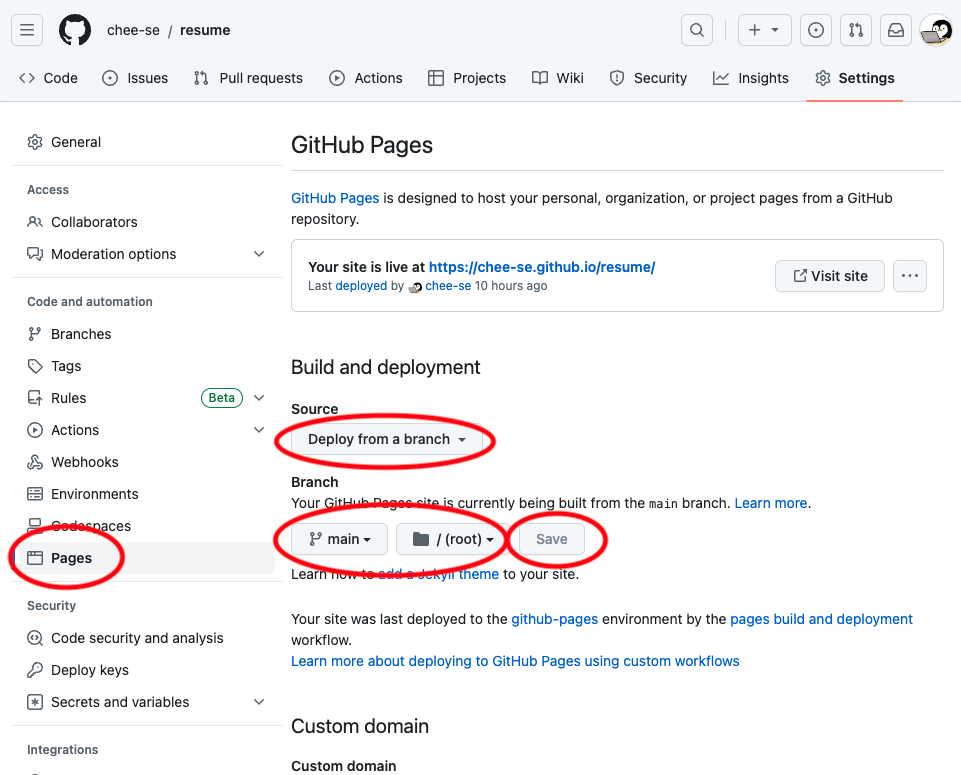
左のメニューから「Pages」をクリックして、
- Source: 「Deploy from a branch」
- Branch: 「main」「root」
を選択して「Save」をクリック。
ここまでできたらURLに実際にアクセスしてみてください。
「https://<ユーザー名>.github.io/<リポジトリ名>」でアクセスできます。
私の場合は「https://chee-se.github.io/resume/」ですね。
以上です。
リポジトリごとにこうしてWebページを公開できるなんて、Githubは本当に便利ですね!
Linuxのコマンド
Linuxのコマンド
よく使うコマンドの一覧 これも基本ですね。
| コマンド | 説明 |
|---|---|
| cd | カレントディレクトリの移動 |
| pwd | カレントディレクトリの表示 |
| ls | ディレクトリの内容の表示 |
| mkdir | ディレクトリの作成 |
| rmdir | ディレクトリの削除 |
| cat | ファイルの内容を表示 |
| less | ファイルの内容をスクロール表示 |
| tail | ファイルの末尾を表示 |
| touch | 空ファイルを作成 |
| rm | ファイルを削除 |
| mv | ファイルを移動/ファイル名を変更 |
| cp | ファイルをコピー |
| ln | シンボリックリンクを作成 |
| find | ファイルを検索 |
| chmod | パーミッションを変更 |
| chown | ファイルオーナーを変更 |
| ps | プロセスを表示 |
| kill | プロセスを停止 |